
Capturing sensor data on your micro:bit is not only quite easy and fun, it is a core use case for the micro:bit and a key factor in its successful adoption in classrooms.
From experimental weather stations, to monitoring the moisture of soil, to checking if an infra-red beam has been broken, school children around the world are being introduced to data science and computational thinking in a fun and accessible way through micro:bit and its data collection options.
This article explores a few concepts associated with taking a large number of consecutive readings, as you might do in the examples above. I am going to show you:
- The benefit of the ‘moving averages’ technique and how to apply it during the data collection process to sample many more data points then you otherwise might.
- How to take advantage of the processing power of the micro:bit to optimise data collection, rather than letting it sleep all the time!
- How to identify points of interest in the data using simple pattern finding.
- Transmit a big pile of data from 1 micro:bit to another. The second micro:bit is connected to an IoT platform using the XinaBox IoT Starter kit.
The following is a list of the sort of ‘use cases’ where these techniques would come in useful:
- measuring radiant light over a 24 hour time period
- measuring the temperature of a room during a meeting
- checking the air quality during rush hour
- measuring the acceleration of a body dropped from a height.
- recording the changes in PH level during an experiment.
Discrete data vs continuous data:
Discreet data:
When we measure data on a micro:bit, whatever it is, we measure it at a specific moment. We measure a data point… one value taken in a single slice of time. That data applies at just that precise moment, not a millisecond before or after. It is a discreet data point.
Sometimes every data point in a set is potentially important. If you are measuring heart-rate and someone has a heart condition, then outliers (points where the data is unusual – e.g. very high or low relative to other points) could be of most interest.
Graphing a heart rate measured over a period of time might look similar to this (although if yours does you should probably see a GP):

In the digital world discreet data is the norm.
Continuous data:
Between any 2 data points in a set of continuous data there are an infinite number of other data points. The actual temperature throughout a day is ‘continuous’.
In the sorts of examples relevant to this blog, and in a LOT of real world examples, we collect discreet data points then analyse the data as if it were continuous data:
We might want to know how levels of UV radiation change as the humidity levels change. Or to look at the rate at which particles are emitted from a radiation source over time. Or perhaps to measure the amount of thrust imparted by an engine. In these cases and many more the trends in the data are of interest.
In cases like these, we (aided by our graphing software) extrapolate values between the points in a data set to look at the trends / patterns. Pretty much any line chart you’ve ever seen does this, including the ones in this blog. Just open a newspaper and you are bound to see line charts being used to make some point or another. We are so used to extrapolating like this that we rarely stop to think about whether the underlying data is discreet or continuous.
So, there are cases where you’ve collected a pile of data, but you are not really interested in individual data points – it is trends and pattern that are of interest. You might want to look at the increase in a pollutant during rush hour and how quickly the pollutant disperses afterwards. Outliers in the data might be caused by a puff of wind blowing a high or low concentration onto the sensor during a reading event, and those points are not of specific interest to you. Indeed, enough of these anomalous readings could obfuscate the pattern of the data that you are looking for.
Graphing pollutant levels over the course of morning rush hour might look something like this:

Using the moving average instead of raw data
So, in some data collection scenarios each individual data point is potentially important. In others, individual data points are of much less importance than the overall pattern.
Lets take a quick look again at the 2 charts I used earlier, this time next to each other:
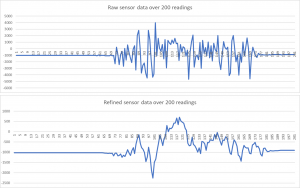
Can you tell that both charts are based on the exact same data set?
Yes: above I have used the SAME 200 data points to generate both charts. I’ve not used any clever charting algorithm either – the charts are just bog-standard ppt line charts.
The pattern is much clearer in the second chart – you would struggle to identify the obvious patterns from looking at the first example though.
The method I’ve used to ‘smooth’ the raw data is simple and is as old as the hills… it is referred to as a moving average:
each data point in the second chart is the average of the 20 data points that preceded it.
You can see for yourself how effective this is at smoothing out the outliers / anomalies and allowing underlying patterns to emerge. There are pros and cons to using this, I should add. I won’t go into detail on these as that is a blog by itself… suffice to say that knowing moving averages are an option in your analysis cannot hurt!
If you have a set of data in Excel it is relatively easy to calculate these moving averages and to chart them, as I have done above.
… and finally we get to the point of this blog….
I was working on a real-world problem using a micro:bit and data collection, and pondering continuous data and moving averages. I wanted to collect as many data points as possible, but was constrained by my technique to a max of about 150. In addition, I’ve always felt antipathy to using sleep() too much, as it feels like a waste to let the processor sit idle! These 3 ingredients led me to an interesting technique that has proven to be very effective in the gathering of data.
Emulating continuous data / moving averages
When collecting a set of many data points on a micro:bit over a period of time, the code one might use often looks something like this:
for i in range(0, 199):
x.append( accelerometer.get_y())
sleep(100)
Above we have a list (or an array) called x and we add 200 values from the accelerometer to it. We add a new value every 100 miliseconds.
This approach will work adequately, but it is flawed… primarily because of the time between readings… for 100 miliseconds we have no data at all. There is a gap between our data points, and 100ms MAY be significant in some contexts.
So, why not just drop the sleep – take it down to 25ms?
This will help, but it’s turtles all the way down I’m afraid – whatever gap we leave between our data readings, we are effectively omitting an infinite number of data points!
So why not drop it all the way down to 1? Or have no sleep period at all – let the only constraint on how often we take readings be the speed of the microprocessor?
The problem with dropping the sleep period is that the amount of data points generated will grow and grow. Too much data could be tricky to work with. We are constrained by data storage and extracting the data later.
The technique I will show you enables the following:
- Take as many readings as is possible, given the speed of the processor
- Emulate the moving averages approach in our data collection
- Take advantage of otherwise idle processor time by removing sleep altogether
The code below is microPython, but the pattern should work in other languages. This code would replace the simple code inside the loop at the beginning of this section:
loopStart = running_time()
accSmoothReading = 0
accSmoothReadings = 0
while( (loopStart + 25) > running_time() ):
accSmoothReading += accelerometer.get_y()
accSmoothReadings += 1
if(accSmoothReadings > 0):
accMovingAverage = accSmoothReading / accSmoothReadings
accReadingList.append(accMovingAverage)
I’ve written a stand-alone microPython demo for micro:bit that shows this technique working… the full, working code is on GitHub here and is well commented, so pop over there if you want a narrative on what each bit of the code does.
The code will record readings of the accelerometer. Each reading is taken at 25ms intervals. Using the no-sleep technique described above EACH data point we record is the average taken across 75 readings! That equates to +/-3000 readings PER SECOND and means that our data set of 150 points takes into account 11,250 separate readings!!! Not bad.
Notes:
- I expect this technique is known to, well, people in the know. I couldn’t find any reference to it on google though, hence this blog. So, until otherwise contradicted I will refer to it as the no-sleep pragmatic data collection pattern (the no-sleep pattern for short)!
Beware:
- the microprocessor on a micro:bit is pretty fast. If you want a long delay between readings you risk overflowing your variables (I seemed to average 3 readings per millisecond). You can add a sleep(1) in the while loop to address this (oh, the irony and hypocrisy of me mentioning this!).
This approach is a lot more hassle than the original version with the sleep, but instead of our data point being 1 reading taken at the beginning of the 25ms period, we are now taking 75 readings throughout that period and recording the average. We’ve built the moving average approach directly into our data collection method and our sample size for each data point is 75 time more reliable. A key implication of this is that we DON’T need to apply the moving average approach to our 150- element data set – it is ALREADY built in to the collection process.
Identifying patterns in the data
In my real world use-case, I am capturing the data on my micro:bit. Later on I put this micro:bit within radio range of my IoT enabled micro:bit gateway (which uses the XinaBox IoT Starter Kit) and transmit the data from the original micro:bit, via the gateway onto an IoT platform.
Transmitting / transferring data from 1 device to another has some small measure of risk. Whether you are using Bluetooth and the pairing gets dropped, or you are using radio and packets do not get through, you will find cases where the process fails (and not because you’ve written dodgy code!). Limiting the amount of data transmitted helps to mitigate against this risk.
The process of transmitting the data is time consuming: for 150 data points it can take 20+ seconds (I am sure my code can be optimised to reduce this, but it will still take some time). It therefore makes sense to remove extraneous data:
In my example I don’t care about ‘leading zeroes’ – I don’t need to transmit the first 30 data points that are all zero. I am interested in the data from the point that it starts to increase – when a force is applied and a meaningful pattern of data begins to develop. The same is true of the end data.
To locate these points of interest I use a simple algorithm:
- take a starting-point in the list of data points. Point0.
- Check if the adjacent value (Point1) is greater or less than the original value.
- Check the next value, Point2 and compare it to Point1.
- Continue a specified number of times.
If the same relationship persists over a number of iterations then this is a pattern. E.g. if the values increase for 6 consecutive readings then we are observing a sustained period of increase which we might call a pattern.
Note that the value ‘6’ is arbitrary – there is no rule we can apply to decide how many recurrences constitute a pattern (although logically 3 must be the minimum). Look at your data, consider what you are measuring and how frequently you take your measurements then choose a number that is logical and makes sense in context.
So the interesting data starts when the first pattern in the data is observed. I use that as my starting point to transmit data.
Similarly, reading the data set ‘backwards’, the beginning of the first pattern detected, which is the last pattern in the data, indicates where to end my data transmissions.
The code could easily be used to identify spikes too, or to identify periods where no pattern is observed. You can find the code, along with loads of comments, here on GitHub. I’ve hardcoded 80 values into the python code, and these are real world values (from the same set I used in the charts).
Transmitting the data to another micro:bit
In my use case, I need to extract the data from the micro:bit and get it somewhere I can use it properly – in this case an IoT platform. I am unable to use Bluetooth for various reasons, so I am going to send the data over radio to another micro:bit.
The second micro:bit is what I call a micro:bit gateway. It is rigged up with the XinaBox IoT Starter Kit (which I helped develop :). This uses Wi-fi to share the data with an IoT platform (I use Ubidots in this example). You can read more about this on my Hackster how-tos. It looks like this:

Sending data over radio from 1 micro:bit to another is pretty straightforward. Also, sending data from a micro:bit gateway to an IoT platform is pretty much solved too.`
But I am trying to send a lot of data (400 data points in my real world example) over radio and simultaneously over Wi-fi. It also seems to take a tad longer to send data over Wi-fi than over radio. The challenge is to ensure both micro:bits involved in the process proceed at a coordinated orderly pace – we don’t want to lose any data.
I’ve not solved this in a clever way at all – I just did the following:
- Increase the length of the radio queue.
- Put excessive delays into the code governing the data collection micro:bit. I did this using simple trial and error – the fewer data points the easier it is.
I’ve written up the full project as a Hackster how-to, which you can find here.